ESM Preprocessing framework
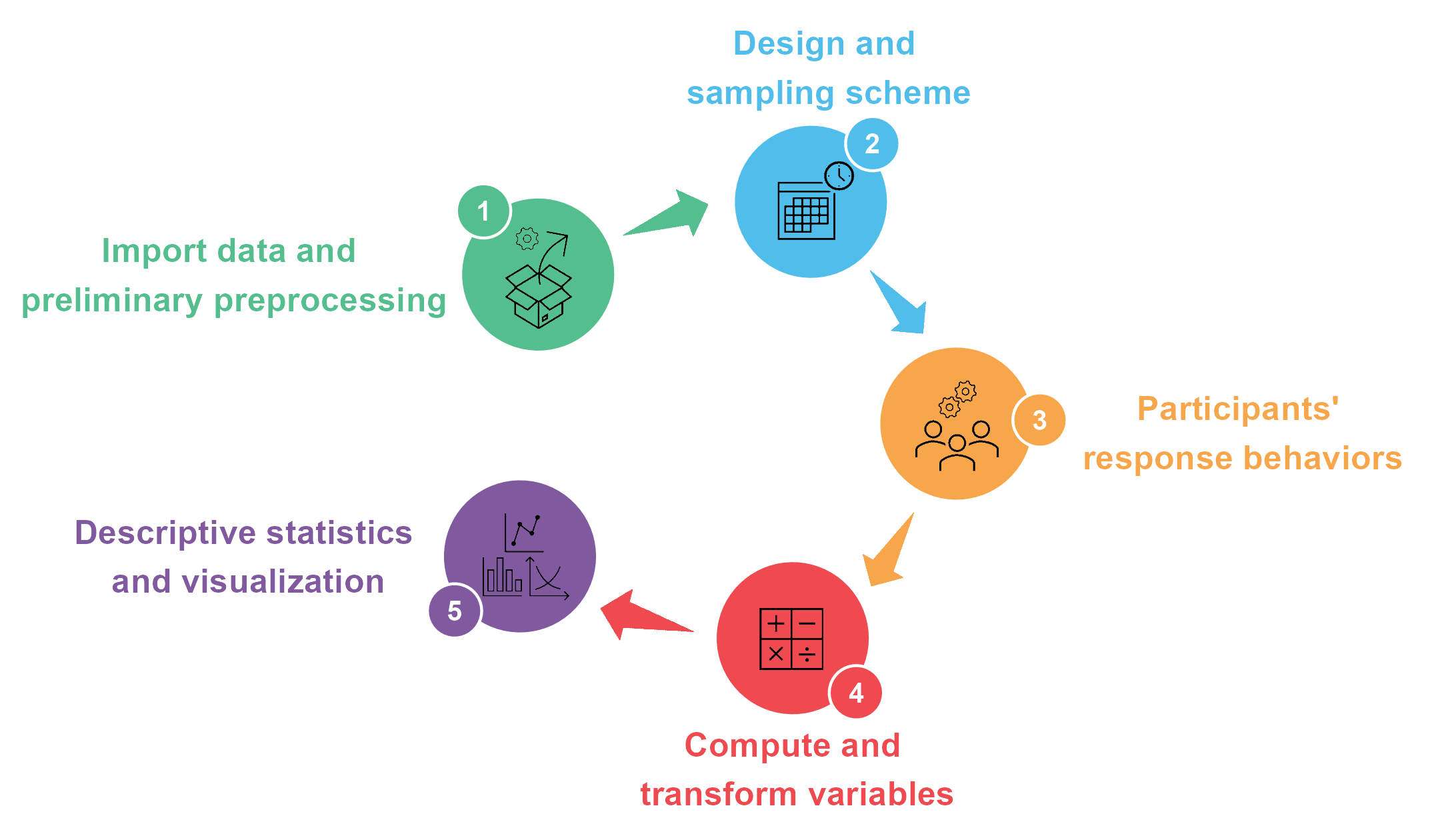
The steps
Step 1: Import data and preliminary preprocessing
In this first step, we import and merge the dataset sources, and perform initial preprocessing tasks, including checking for duplicate observations, variable reformatting, variable renaming, and getting an overview of missing values. Moreover, ESM studies encompass various types of variables, such as subject identifier variables (e.g., participant numbers), time-varying variables (e.g., positive/negative affects), time-invariant variables (e.g., demographics, personality traits), etc. For each, there are specific expectations regarding their properties and values (e.g., range of values, missing values). It is crucial to investigate any potential violations of these expectations. By going through this initial preprocessing step, we gain a better understanding of the dataset’s structure and content, which is crucial before delving into more ESM-specific preprocessing steps.
Step 2: Design and sampling scheme
This step entails evaluating the extent to which the sampling scheme and study design were adhered to during the data collection process. We examine adherence with the predefined guidelines by, mainly, analyzing the recorded timestamps. These timestamps, in particular the ‘scheduled’ and ‘sent’ variables in the dataframe, provide valuable information on how closely the actual data collection process aligned with the intended sampling scheme and study design. For instance, we can compare the scheduled timestamps (predefined before the study) with the actual recorded timestamps for each beep, we can gain insights into any deviations from the predefined guidelines.
Step 3: Participants response behaviors
In this step, we investigate whether participants follow the sampling scheme correctly and avoid any patterns of response that could compromise data quality or introduce bias. In the literature, three principal aspects are investigated which are the compliance rates, the careless responding, and the delay of response. We broaden the scope by including the investigation to any other pattern of responses (e.g., age explaining response rate). Understanding participant response behaviors enables appropriate treatment of these behaviors (e.g., as control variables, group variables, set as missing values), enhancing data quality and strengthening the validity of the results.
Step 4: Compute and transform variables
In ESM research, it is common to use a group of items to capture a specific construct. Therefore, this step involves calculating scores of interest (e.g., affect constructs) and making necessary modifications (e.g., centering, lagging) to prepare the data for analysis. It is crucial to choose appropriate methods that consider the data structure (e.g., nesting within participants, serial order of observations) in order to avoid computation issues. Additionally, one must check for any issues in the created variables. This step may also include the computation of psychometric properties for the scores.
Step 5: Descriptive statistics and visualization
In this step, we focus on obtaining descriptive statistics that provide valuable knowledge. We can visualize the variables or their associations (e.g., correlations, distributions) to have a better understanding of the construct associated which can have important implications for statistical modeling (e.g., floor/ceiling effect). Focusing on participants, we can investigate within and between differences using descriptive statistics and visualizations (e.g., time series). This descriptive and visual analysis complements statistical models, which often focus on extracting specific features or parameters.
Reporting
Reporting the preprocessing steps is crucial for enhancing transparency and reproducibility as well as improving information sharing among collaborators. However, the preprocessing steps are often overlooked and not adequately documented.
To address this issue, we propose to create a preprocessing report which provides a comprehensive account of the preprocessing procedures, including any modifications made to the data. The purpose of this report is to share “what has been done” on the raw dataset to get the preprocessed one. Secondly, we recommend creating a data quality report for the preprocessed dataset. It would highlight important quality aspect (e.g., sampling scheme, participants’ response behaviors) and also offer a detailed description of the dataset’s variables, similar to a codebook. This report provides valuable insights for collaborators or future users of the dataset, allowing them to quickly assess its quality and understand its characteristics.
To assist researchers in generating these reports, we have developed Rmarkdown templates available in the esmtools package. These templates serve as a starting point, guiding researchers in creating the preprocessing report and the data quality report. Detailed instructions on utilizing these templates can also be found on the website, which offers additional resources and information on best practices.
Required materials and metadata for preprocessing
When preprocessing your data, the availability of some materials and metadata can be essential as it helps to understand the dataset’s contents and structure. Here is a (non-exhaustive) list of the materials and variables that you should have:
Timestamp variables: These include ‘scheduled’, ‘sent’, ‘start’, and ‘end’ timestamps, which are essential for analyzing the timing and sequence of observations.
Codebook: Creating a codebook before data collection and updating it during preprocessing is essential. The codebook facilitates the entire preprocessing process, from the initial data examination to the final analysis, by documenting variable names and any modifications made.
Track files: Maintaining track files documenting issues and changes that occurred during or after data collection and preparation is highly recommended. These files serve as a valuable reference for maintaining a clear audit trail but can be vital to understand the dataset’s particular (and unexpected) characteristics.
Data management plan: A data management plan outlines how the data should be stored, shared, and managed. This plan ensures consistency in data handling and helps maintain data integrity throughout the preprocessing and analysis stages. In addition, it helps to understand which aspect of the dataset can be shared knowing that data visualization in the reports can already share information.