First missingness analysis
Packages: dplyr, psych, naniar, visdat, tidyr
During the preprocessing of ESM data, it is essential for researchers to thoroughly investigate and understand the origin of missing values as they can introduce bias and compromise the integrity of the analysis. In ESM studies, missingness in data can be principally attributed to the data collection procedure/application, characteristics of the participants or, in last resort, to wrong data manipulation. Consequently, step 2 and 3 of the framework are dedicated to addressing these factors and, overall, we introduce how to best handle data to not implement further missingness issues. This particular section aims to introduce the fundamental concepts of handling and exploring missing values. We will focus on crucial aspects (e.g., the coding of missing values), and provide functions that facilitate gaining an overview of missingness within the dataset, that will can later be useful in completing step 2 and 3 of the framework.
(Re-)code missing values
An initial check in the data preprocessing is to ensure that missing values have been accurately coded (i.e., ‘NA’ in R). Inaccurate missing value coding is a serious threat as R will treat missing values as existing ones. In this context, even the average of a variable could be highly biased, for instance, if -999 is used as missing code. Fortunately, it is often straightforward to verify the coding of missing values as it is often due to different coding usage by other software (e.g.,“na”, “-999”). For instance, we can perform certain checks for each variable:
- range of values: whenever missing values are coded using numerics, they are often very low or high values. Hence, we can check the range of numerical variables using descriptive functions (e.g., ‘summary()’, ‘psych::describe()’, ‘skimr::skim()’). In our example, the minimum values of the variables ‘PA2’ to ‘NA3’ are ‘-999’. Note, the timestamp variables are not numeric and can thus not be summarized in this way.
- format: some softwares uses character values such as ‘__na__’. In R, those variables are formatted, by default, into characters. Hence, the only option is to inspect the unique values of those variables. Based on the previous output, we see that ‘PA1’ shouldn’t be character formated as it contains numeric values. Below, we inspect ‘PA1’ unique values and we see that it contains ‘__na__’.
psych::describe(data) vars n mean sd median trimmed mad min max range skew
dyad 1 4200 15.50 8.66 15.5 15.50 11.12 1 30 29 0.00
role 2 4200 1.50 0.50 1.5 1.50 0.74 1 2 1 0.00
obsno 3 4200 35.50 20.21 35.5 35.50 25.95 1 70 69 0.00
id 4 4200 30.50 17.32 30.5 30.50 22.24 1 60 59 0.00
age 5 4200 35.10 9.79 35.5 34.40 15.57 25 65 40 0.55
cond_dyad* 6 4200 1.50 0.50 1.5 1.50 0.74 1 2 1 0.00
scheduled 7 4198 NaN NA NA NaN NA Inf -Inf -Inf NA
sent 8 4200 NaN NA NA NaN NA Inf -Inf -Inf NA
start 9 2946 NaN NA NA NaN NA Inf -Inf -Inf NA
end 10 2946 NaN NA NA NaN NA Inf -Inf -Inf NA
contact 11 2946 0.12 0.33 0.0 0.03 0.00 0 1 1 2.30
PA1* 12 3607 16.97 21.97 6.0 12.25 7.41 1 95 94 1.60
PA2 13 2594 5.79 125.94 18.0 17.46 23.72 -999 100 1099 -7.62
PA3 14 3045 7.46 127.28 15.0 17.29 20.76 -999 100 1099 -7.44
NA1 15 3045 5.56 127.17 10.0 15.24 13.34 -999 100 1099 -7.41
NA2 16 2753 -6.09 128.53 7.0 8.12 8.90 -999 83 1082 -7.53
NA3 17 2518 35.13 178.51 73.0 66.50 29.65 -999 100 1099 -5.47
location* 18 3048 4.92 1.56 5.0 4.96 1.48 1 7 6 -0.21
kurtosis se
dyad -1.20 0.13
role -2.00 0.01
obsno -1.20 0.31
id -1.20 0.27
age -0.48 0.15
cond_dyad* -2.00 0.01
scheduled NA NA
sent NA NA
start NA NA
end NA NA
contact 3.27 0.01
PA1* 1.80 0.37
PA2 57.92 2.47
PA3 56.07 2.31
NA1 55.84 2.30
NA2 55.22 2.45
NA3 28.76 3.56
location* -0.97 0.03unique(data$PA1) [1] "__na__" NA "1" "23" "14" "6" "26" "24"
[9] "32" "17" "15" "19" "21" "11" "13" "8"
[17] "9" "25" "29" "31" "3" "4" "20" "5"
[25] "33" "30" "38" "16" "10" "7" "22" "27"
[33] "18" "28" "37" "46" "36" "2" "12" "34"
[41] "49" "43" "44" "51" "55" "68" "57" "41"
[49] "52" "45" "54" "53" "47" "42" "40" "39"
[57] "35" "87" "83" "85" "86" "82" "90" "88"
[65] "84" "81" "80" "79" "78" "92" "62" "65"
[73] "64" "59" "63" "73" "58" "61" "66" "60"
[81] "70" "67" "69" "100" "96" "97" "99" "93"
[89] "91" "75" "48" "56" "94" "50" "89" "98" Multiple methods can be used to replace the wrong missingness code values (target values) with ‘NA’ values:
- Method 1: replace the target value in a character variable. We replace ‘__na__’ in the ‘PA1’ variable.
- Method 2: replace the target value in a numerical variable. We replace ‘-999’ in the ‘PA2’ variable.
- Method 3: replace the target value in a subset of variables. Here, we replace ‘0’ with ‘NA’ in ‘PA1’ and ‘PA2’ variables.
- Method 4: replace the target value in the whole dataset. Be careful with this method. A problematic value in one variable can be normal in another variable. Here, we transform ‘-999’ values as it is not an expected value in any variable.
data$PA1[data$PA1 == "__na__"] = NA
# OR:
# data$PA1 = gsub("__na__", NA, data$PA1)data$PA2[data$PA2 == -999] = NADon’t forget to reformat variables whenever necessary:
data$PA1 = as.numeric(data$PA1)The described above are ‘ideal’ cases. Worst-case scenario is when the missing value code takes expected values for particular variables (e.g., 0). Consequences are that it is much more difficult to discover this issue and it can have important implications for any conclusions drawn based on statistics. Nonetheless, an in depth understanding of your dataframe may alarm you when encountering specific patterns. For instance, if you encounter an observation where a participant rated ‘0’ values on all self-reported variables (e.g., positive and negative affect items), you might want to explore more if it can be due to careless responding or a problematic missing value coding.
Further replacement functions
Many other functions from different packages provide relevant functions to handle miss-coded missing values. In particular, the naniar package contains three functions:
- ‘replace_with_na()’ function replaces target values of each variable specified. In particular, each variable is associated with a vector of target values to replace with ‘NA’.
- ‘replace_with_na_at()’ function replaces target values (through condition) in a subset of variables.
- ‘replace_with_na_all()’ function replaces target values (through condition) in the whole dataset.
library(naniar)
data = replace_with_na(data,
replace = list(PA1 = c("N/A", "__na__", "missing"),
PA2 = c("N/A", "__na__", "missing")))Overview of missing values
The following functions and visualizations aim to have an overview of how missing values are distributed in the dataframe. It allows us to easily understand the extent of missing data in the dataset and identify patterns, notably by looking at occurrences of missing values between variables. We will mainly use two libraries that have been made for such a purpose: naniar and visdat.
library(naniar)
library(visdat)With the following plot, we can gain an overall graphical visualization of the missingness in the dataframe. In the plot, on the y-axis are the observations and on the x-axis the variables of the dataset. Intersections of rows and columns are cells that provide different information. Two similar functions can be used:
- ‘vis_miss()’ which colors cells in the following way: black indicates a missing cell and grey indicates a present cell.
- ‘vis_miss(.,cluster=TRUE)’ similar to the above, but additionally observations are reoganized to cluster the patterns of missingness together.
- ‘vis_dat()’ which colors cells in the following way: black indicates a missing cell and other colors indicate which type of values cells contain (e.g., numerical, character).
vis_miss(data)
vis_miss(data, cluster=TRUE)

In the previous plots, it is often required to increase their height. Indeed, when a pattern of missingness is seldom and the height of the plot is too small, the black cells are not visible and you might miss important information. This can be done in Rmarkdown by specifying the height of the plot in the chunk options (e.g., fig.height = 10).
Also displayed in the previous plots, we can compute the number of missing values (or their percentage) per variable. We can simply use the ‘miss_var_summary()’ function to do so.
miss_var_summary(data)# A tibble: 18 × 3
variable n_miss pct_miss
<chr> <int> <dbl>
1 NA3 1753 41.7
2 PA2 1694 40.3
3 PA1 1683 40.1
4 NA2 1492 35.5
5 start 1254 29.9
6 end 1254 29.9
7 contact 1254 29.9
8 PA3 1201 28.6
9 NA1 1201 28.6
10 location 1198 28.5
11 scheduled 2 0.0476
12 dyad 0 0
13 role 0 0
14 obsno 0 0
15 id 0 0
16 age 0 0
17 cond_dyad 0 0
18 sent 0 0 Next, we can explore the occurrence of the number of missing values per row/observation. Researchers can identify if the numbers of missing values per observation occur systematically or if they are more randomly determined. To visualize the proportion of NA per observation, we propose two methods:
- ‘gg_miss_case()’ from the naniar package: on the x-axis is the observation number and on the y-axis is the number of missing values within the variables of each observation. This graph provides valuable insights, particularly in terms of identical proportions of missing values across multiple observations and how this proportion changes over the course of the dataset’s observations.
- ggplot script: it is more difficult to create but has the advantage to offer more flexibility. The x-axis is the number of missing values per row and the y-axis is their occurrences.
gg_miss_case(data)

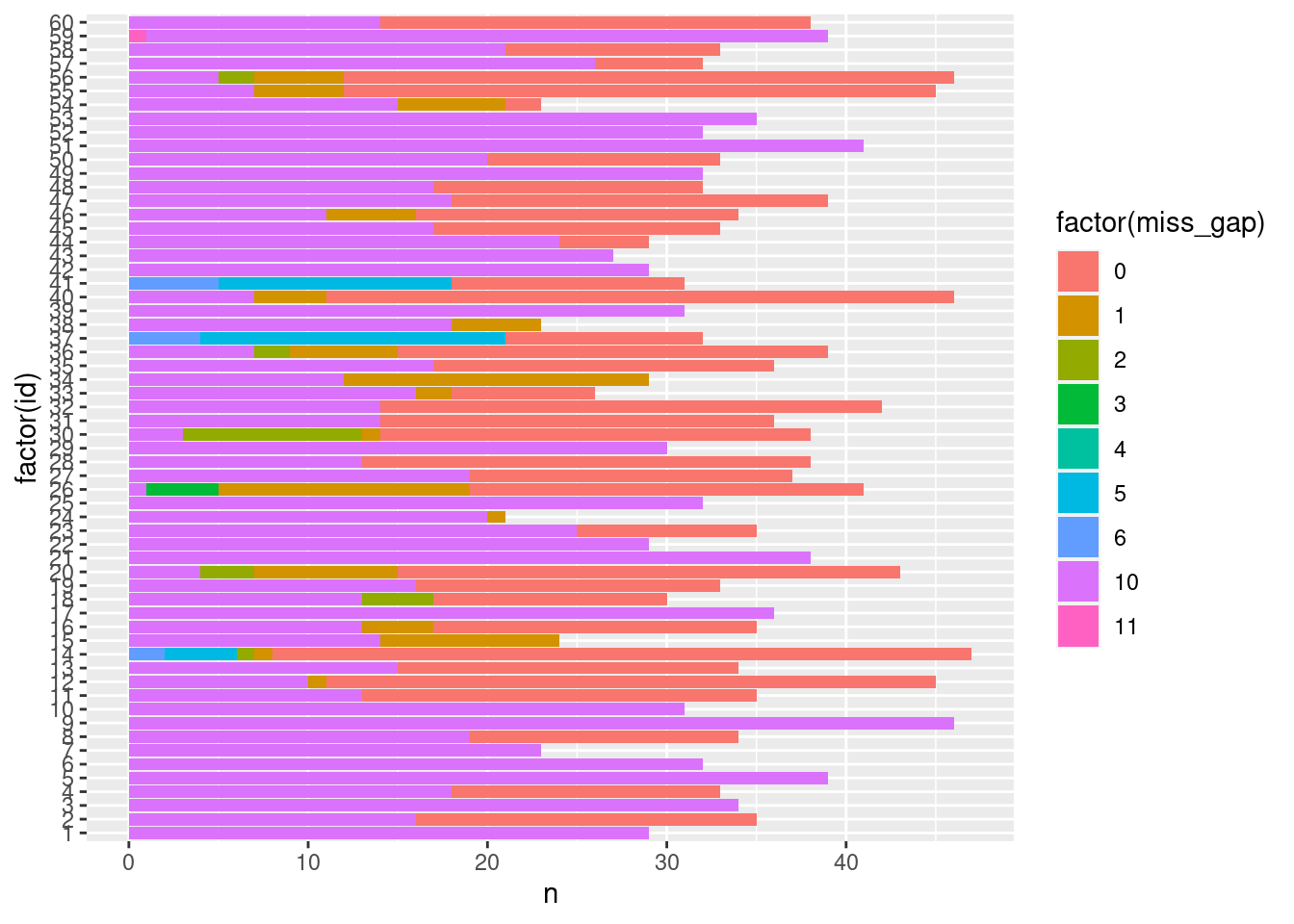
We can explore missing values grouping by participants. However, it is a more complex exploration as missing values are now grouped in observations/variables which we nest within participants. We propose three methods:
- Occurrence of missing values: if observations contain either no or only missing values (in self-report items), we can use a variable to account for the number of missed beeps by the participant.
- Occurrence of missing values within variables: we can investigate if missingness between variables is identical across participants. Hence, we want to visualize the occurrence of missing values within each variable for each participant. It is particularly relevant if participants were allowed to answer only part of the questionnaires.
- Occurrence of the number of missing values per row/observation: we investigate how the number of missing values per row/observation occurs within participants. It is particularly relevant if participants were allowed to answer only part of the questionnaires.
data %>%
group_by(id) %>%
summarise(PA1_miss = sum(is.na(PA1))) %>%
ggplot(aes(x=factor(id), y=PA1_miss)) +
geom_col()

Digging deeper
Correlates
To explore patterns in missingness between variables, a set of functions can be used to examine potential dependencies or relationships in missing values between variables as well as investigate potential variables influencing missingness.
The ‘gg_miss_upset()’ function enables us to visualize the overlap and combinations of missing values across different variables. The lower part of the plot showcases the distinct patterns of missingness between variables, while the upper plot depicts the occurrences of each of these patterns. When using this function, we need first to select a subset of variables.
gg_miss_upset(data[,c("PA1","PA2","PA3","NA1","NA2","NA3")])
Missing value occurrences can be associated with specific factors. To investigate those factors, we can split previous plots according to another categorical variable of interest. For instance, we could make the hypothesis that the treatment condition would have an influence on the proportions or the patterns of missing values. To showcase, we use two methods to display the occurrence/proportion of the number of missing values per row in the function of the treatment condition of the participants.
- ‘gg_miss_case’ with the ‘facet’ argument
- ‘gg_miss_fct’ with the ‘fct’ argument
gg_miss_case(data, facet=cond_dyad)

Conditional distribution
Visualizing the distribution of a variable based on the presence or absence of missing values in another variable can provide valuable insights (e.g., can help better understand the impact of missing values on the analysis). It is particularly valuable when participants can choose whether or not to answer each question in a questionnaire. Using the ‘bind_shadow()’ function (create dummy coding to specify if a variable is a missing value or not), we can investigate the distribution of ‘NA1’ or the conjoint distribution of ‘NA1’ and ‘NA2’ conditioning for the missingness in ‘PA3’ using:
- A density plot: we plot the distribution of the variable ‘NA1’ conditionning for missing values in ‘NA3’ (color legend). We see that the occurrence of missing values in ‘PA3’ seems to influence the distribution of ‘PA1’.
- A scatter plot: we plot a scatter plot with ‘PA1’ on the x-axis and ‘PA2’ on the y-axis conditionning for missing values in ‘NA2’ (color legend). We see that the occurrence of missing values in ‘PA3’ does not seem to influence the joint distribution of ‘PA1’ and ‘PA2’.
data %>%
bind_shadow() %>%
ggplot(aes(x= NA1, color = NA2_NA)) +
geom_density()
